What is RAG(Retrieval-Augmented Generation)?
What is RAG and why do we need it?
Before discussing about RAG application, let's first understand what problem we're trying to solve.
Problem
Let's assume you have a small business and you're building a chatbot to answer user's queries about your products and services. At first, you're thinking of using either a search engine or use a LLM(Large Language models) such as Open AI.
There are problems in either approach.
Problem in using using search engine:
- Usually, search engines may calculate relevancy based on the keyword match and number of links(backlinks) pointing to that particular document. For small set of data(just as your website), this method of calculating relevancy may not be appropriate as there would not be much backlinks.
- And, you don't want to send bunch of links to the user. Users don't have much patience to go through links and read them. Users want to get their answers qucikly and as accurate as possible.
Problem in using LLM directly:
- LLM will not have information about your product or service. So, you need to send information about product or service to LLM so that it can answer user's query.
- Context is information you send to LLM along with your query. Each LLM will have context limit. You can't send hundreds of documents to ChatGPT and ask it to answer user's query.
So, what is the solution?
This is where RAG application comes into picture.
RAG (Retrieval-Augmented Generation) solution
Let's say you like to build a chatbot on your website to answer user's queries on your product/ service.
You may need to 2 things
- Indexing: Get the list of documents based on which your chatbot should answer the user's queries. We would convert each document into higher dimensional array(more on this later) so that it would be easier to do semantic search when user queries our chatbot. Semantic search is a type of search where query is matched against documents based on meaning rather than keyword density or backlinks.
- Querying: We need to find relevant documents based on the user's query and answer them in conversational manner.
Please note that the above 2 steps are related to each other. Finding relevant documents depends on how you store the data.
We'll discuss about technical details in next section. As of now, we'll discuss about the high level process.
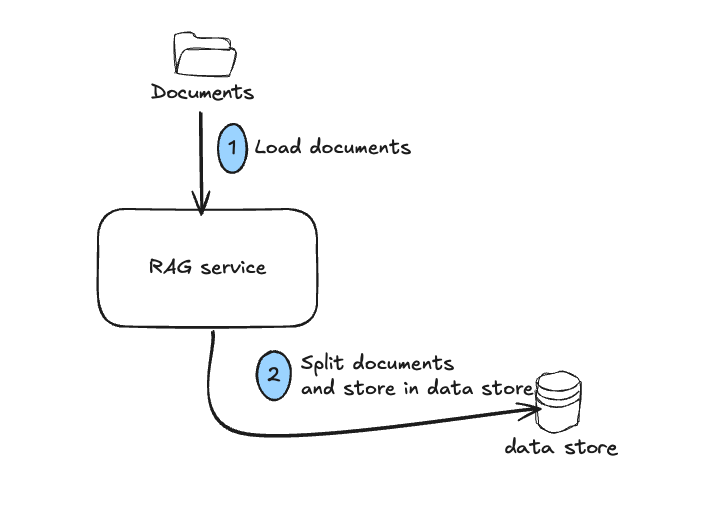
Indexing
Indexing is pretty simple. You just get the list of all of your documents and store it in some data store in a manner so that it will easier to do semantic search rather than doing simple word match. You may need to split the document based on the document length.
Why splitting the document is necessary?
Let's assume your web page has 30,000 words. If we store all 30,000 words in a single row in data store, it would be difficult to compare with users's query. If we split the document into 60 parts where each part containing 500 words, your RAG solution can answer in accurate manner.
Querying
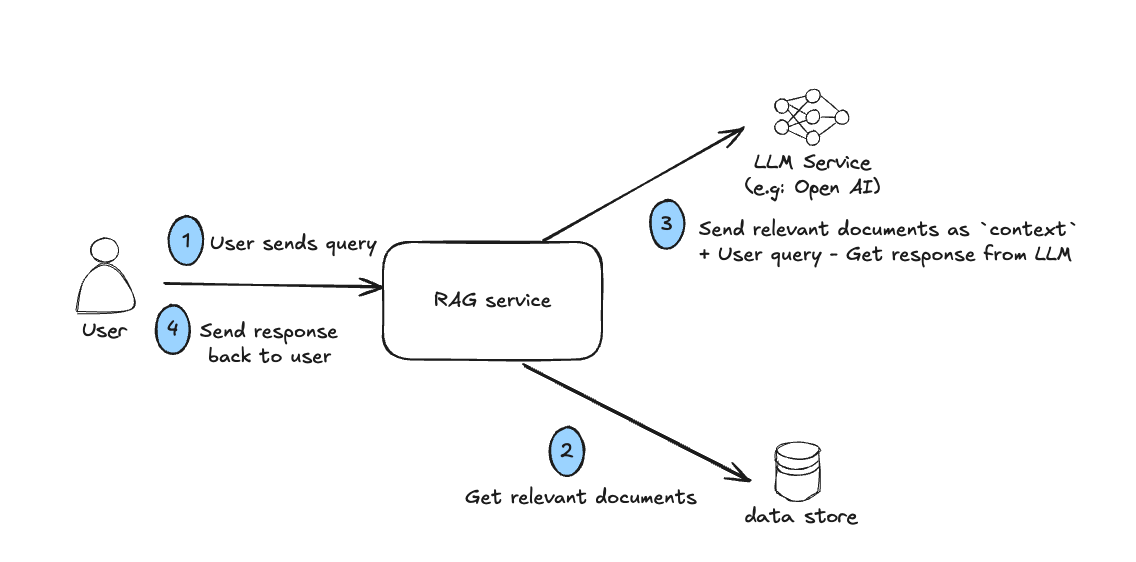
Now, let's assume your user is trying to query your chatbot for some information about your product or service.
First we need to convert the user's query into a specific format and then compare with documents parts that we've stored earlier during indexing process.
Now, we would have got relevant document parts which may answer user's query. But, we can't send these document parts directly to user. The expectation of the chatbot is to provide relevant answers as accuate as possible and in a conversational manner.
So, we'll send the relavent documents to LLM(such as Open AI) along with user's query and ask LLM to provide answer in conversational manner.
LLM will provide the answer which we would send it to user.
Note: Please note that there are some additional steps involved in indexing and querying. We'll discuss them in upcoming section.