Semantic Search
How it works.
In previous section, we mentioned that we need to convert the document data(which is usually text) in higher dimentional array.
In this section, we can discuss about why we need to convert the text data into higher dimentional array and what are the benefits in doing so.
How it works
Let's take couple of sentences
- Cat says meow
- Dog will bark
Model can convert text to array of numbers(called embeddings) taking into word context and word order so that semantically similar words are put together.
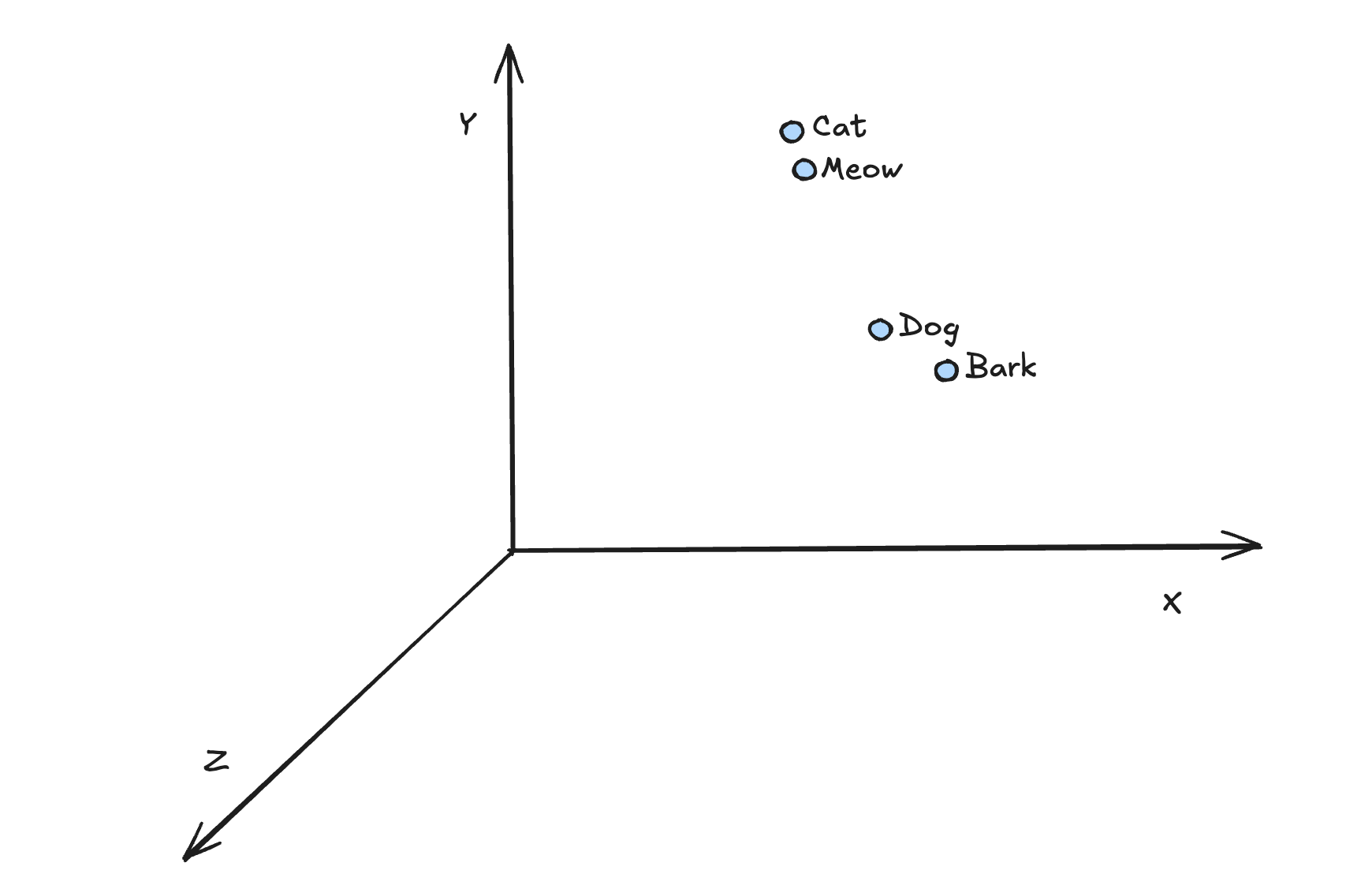
When I convert above 2 sentences and map into 3D space, the model may place the words something like below.
As you can see, the words "cat" and "meow" are sematically related and hence they are closer to each other. Likewise, the words "dog" and "bark" are sematically related and are closer to each other in this 3D space.
Please note that this is just for illustration. Actually embeddings will be of higher order dimensions.
In this example, I've shown 3 dimensional space. Actual production grade embedding model will be of higher dimensions.
For example, text-embeddings-3-small of openai will have vector length of 1536 and text-embedding-3-large will have vector legth of 3072.
The idea of converting text to higher dimensional vector is to put semantically words together as it will be easier to compare
We've learnt that we need to use some embedding model to convert the text to vectors so that semantically related data would be put closer.
Where to store the embeddings
We can't store these vectors as primitive data types available in database. These are many 3rd party vector stores available in the market.
The objective of this tutorial is understand the basics and build a simple RAG application. So, as part of these tutorial, we're going to use simple postgres database.
There is an extension pgvector which enables us to store vector data and do the processing on the same.